来做一些树形DP的经典题目吧。
开始开始!
两者的本质一致,只不过是在处理数据时的迭代方式不同了而已。最大子段和 和最大子树和
前者是 给出一个长度为 n 的序列 a,选出其中连续且非空的一段使得这段和最大。
后者是 给出一个节点数为 n 的树 a,选出其中几个连续节点(包括根节点)的非空集合使得这段和最大。
两者的思想一模一样,只有迭代的方式 不一样。
话说DP好像本来就算不上是算法 )。
一棵树中两个节点之间的最远距离。
如果单纯地讨论这个问题,可以通过跑两次DFS实现,后面有讲找所有点能到的最远距离,这里就不多讲了。DFS法求树的直径
那么怎么通过树形DP解决该问题呢?
设 f 1 [ i ] f1[i] f 1 [ i ] i i i i i i f 2 [ i ] f2[i] f 2 [ i ] i i i i i i s o n son s o n i i i w [ i ] [ s o n ] w[i][son] w [ i ] [ s o n ] s o n son s o n i i i
1 2 3 4 5 6 7 8 9 if ( f1[i] < f1[son] + w[i][son] ) { f2[i]=f1[i]; f1[i]=f1[son]+w[i][son]; } else if ( f2[i] < f1[son] + w[i][son] ){ f2[i]=f1[son]+w[i][son]; }
最后的直径则是 ( f 1 [ i ] + f 2 [ i ] ) (f1[i]+f2[i]) ( f 1 [ i ] + f 2 [ i ] )
如果是邻接表的话则是:
1 2 3 4 5 6 7 8 9 10 11 void dp (int x) v[x]=1 ; for (int i = head[x]; i; i = nxt[i]){ int j = to[i]; if (v[j]) continue ; dp (j); ans = max (ans, d[x] + d[j] + w[i]); d[x] = max (d[x], d[j] + w[i]); } }
最后直径就是 ans 的值。
找一个点,使其所有子树中的最大子树节点数最少(或从此点将树分成两半,分成的两棵树权值差最小),该点即为该树的重心。
可用DFS求解DFS法求树的重心
洛谷P1364:医院设置 给定一棵带权二叉树,相邻两节点之间距离为 1 ,求出该树的重心,使每个点到重心的距离与点的权值的乘积 的总和 最小。
设 f [ i ] f[i] f [ i ] i i i s i z e [ i ] size[i] s i z e [ i ] i i i 显然 ,a n s = m i n f [ i ] , 1 < = i < = n ans = min { f[i] , 1 <= i <= n } a n s = m i n f [ i ] , 1 < = i < = n f f f f f f f [ 1 ] f[1] f [ 1 ] i i i j j j j j j i i i
f [ j ] = f [ i ] + s i z e [ 1 ] − s i z e [ j ] − s i z e [ j ] f[j] = f[i] + size[1] − size[j] − size[j] f [ j ] = f [ i ] + s i z e [ 1 ] − s i z e [ j ] − s i z e [ j ]
当我们从 i i i j j j i i i j j j j j j j j j i i i s i z e [ j ] size[j] s i z e [ j ] s i z e [ 1 ] size[1] s i z e [ 1 ] s i z e [ j ] size[j] s i z e [ j ] s i z e [ 1 ] size[1] s i z e [ 1 ] s i z e [ j ] size[j] s i z e [ j ] j j j 参考博客
这篇代码是蛮早写的,码风和后面不一致,敬请谅解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <bits/stdc++.h> using namespace std;int n,a,b,l,r,cn;int dd[10000 ],f[100000 ],to[10000 ],next[10000 ],head[10000 ],w[10000 ];int ans=0x3f3f3f3f ;int dfs ( int u , int fa , int dep ) dd[u] = w[u]; for ( int i = head[u] ; i ; i = next[i] ) { if ( to[i] != fa ) { dfs ( to[i] , u , dep+1 ); dd[u] += dd[to[i]]; } } f[1 ] += w[u] * dep; } int dp ( int u , int fa ) for ( int i = head[u] ; i ; i = next[i] ) { if ( to[i] != fa ) { f[to[i]] = f[u] + dd[1 ] - dd[to[i]]*2 ; dp ( to[i] , u ); } } ans = min ( ans , f[u] ); } int main () scanf ("%d" ,&n); for ( int i = 1 ; i <= n ; i ++ ) { scanf ("%d%d%d" , &w[i] , &l , &r); if ( l ) { to[++cn] = l; next[cn] = head[i]; head[i] = cn; to[++cn] = i; next[cn] = head[l]; head[l] = cn; } if ( r ) { to[++cn] = r; next[cn] = head[i]; head[i] = cn; to[++cn] = i; next[cn] = head[r]; head[r] = cn; } } dfs ( 1 , 0 , 0 ); dp ( 1 , 0 ); printf ("%d" ,ans); return 0 ; }
这里还有道进阶的题目 (就当做习题好了) 。我有时间写。。。吧 POJ-3140:Contestants Division
最大子树和 给出一个节点数为 n 的树 a,选出其中几个连续节点(包括根节点)的非空集合使得这段和最大。
前面说了树形DP与线性DP思想一致,在这题上就能得到充分体现。f [ i ] [ 1 ] f[i][1] f [ i ] [ 1 ] i i i f [ i ] [ 0 ] f[i][0] f [ i ] [ 0 ] i i i
f [ i ] [ 1 ] + = m a x f [ s o n ] [ 1 ] , f [ s o n ] [ 0 ] f[i][1]+=max { f[son][1] , f[son][0] } f [ i ] [ 1 ] + = m a x f [ s o n ] [ 1 ] , f [ s o n ] [ 0 ]
f [ i ] [ 1 ] f[i][1] f [ i ] [ 1 ]
附上代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <bits/stdc++.h> using namespace std;int n, x, y;int a[17000 ], v[17000 ], f[17000 ][2 ];vector < int > son[17000 ]; void find (int root) f[root][1 ] = a[root]; f[root][0 ] = 0 ; for (int i = 0 ; i < son[root].size (); i++) { int y = son[root][i]; find (y); f[root][1 ] += max (f[y][1 ], f[y][0 ]); } } int main () scanf ("%d" , &n); for (int i = 1 ; i <= n; i++) { scanf ("%d" , &a[i]); } for (int i = 1 ; i < n; i++) { scanf ("%d%d" , &x, &y); son[y].push_back (x); v[x] = 1 ; } for (int i = 1 ; i <= n; i++) { if (!v[i]) { find (i); printf ("%d" , max (f[i][0 ], f[i][1 ])); } } return 0 ; }
仔细观察发现, f [ i ] [ 0 ] f[i][0] f [ i ] [ 0 ] f [ i ] [ 0 ] f[i][0] f [ i ] [ 0 ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <bits/stdc++.h> using namespace std;int n, x, y;int a[17000 ], v[17000 ], f[17000 ];vector < int > son[17000 ]; void find (int root) f[root] = a[root]; for (int i = 0 ; i < son[root].size (); i++) { int y = son[root][i]; find (y); f[root] += max (f[y], 0 ); } } int main () scanf ("%d" , &n); for (int i = 1 ; i <= n; i++) { scanf ("%d" , &a[i]); } for (int i = 1 ; i < n; i++) { scanf ("%d%d" , &x, &y); son[y].push_back (x); v[x] = 1 ; } for (int i = 1 ; i <= n; i++) { if (!v[i]) { find (i); printf ("%d" , f[i]); } } return 0 ; }
没有上司的舞会 经典老题
给出一棵带权树,要求相邻的两点不能同时取,求能取到的最大权值和。
同样地,每个点有两种状态,取或不取。f [ i ] [ 1 ] f[i][1] f [ i ] [ 1 ] f [ i ] [ 0 ] f[i][0] f [ i ] [ 0 ] 不 取根节点时子树取到的最大值。
有没有发现这道题和最大子树和非常像? 唯一的区别就是后者比前者多了一个约束条件:相邻的两个点不能同时取。
$ f[i][1] += f[son][0] ;
当取根节点时,它的儿子节点只能不取; 当不取根节点时,它的儿子节点可以选择取或不取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <vector> using namespace std;int n;vector < int > son[10000 ]; int f[10000 ][2 ], v[10000 ], h[10000 ];void find (int x) f[x][1 ] = h[x]; f[x][0 ] = 0 ; for (int i = 0 ; i < son[x].size (); i++) { int y = son[x][i]; find (y); f[x][1 ] += f[y][0 ]; f[x][0 ] += max (f[y][1 ], f[y][0 ]); } } int main () scanf ("%d" , &n); for (int i = 1 ; i <= n; i++) { scanf ("%d" , &h[i]); } for (int i = 1 ; i < n; i++) { int x, y; scanf ("%d%d" , &x, &y); son[y].push_back (x); v[x] = 1 ; } for (int i = 1 ; i <= n; i++) { if (!v[i]) { find (i); printf ("%d" , max (f[i][1 ], f[i][0 ])); break ; } } return 0 ; }
二叉苹果树 这也是道经典题目。
给定一棵带权二叉树,要求减掉几条枝,求保留 m m m
设 f [ i ] [ j ] f[i][j] f [ i ] [ j ] i i i j j j m m m
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <bits/stdc++.h> using namespace std;int n, m, a, b, cn, c;int to[100009 ], head[100009 ], nxt[100009 ], w[1000009 ], f[10000 ][1000 ];void dfs (int x) for (int i = head[x]; i; i = nxt[i]) { int y = to[i]; dfs (y); for (int j = m; j >= 1 ; j--) { for (int k = j - 1 ; k >= 0 ; k--) { f[x][j] = max (f[x][j], f[x][j - k - 1 ] + f[y][k] + w[i]); } } } } int main () scanf ("%d%d" , &n, &m); for (int i = 1 ; i < n; i++) { scanf ("%d%d%d" , &a, &b, &c); nxt[++cn] = head[a]; to[cn] = b; head[a] = cn; w[cn] = c; } dfs (1 ); printf ("%d" , f[1 ][m]); return 0 ; }
OK,基础应用讲的差不多了,接下来看几题例题。
选课 又一题经典老题 (比本蒟蒻还大10岁)
一个背包,容量为 M ,物品总数为 N ,每个物品体积为 1 ,价值为 s [ i ] s[i] s [ i ]
这道题其实稍微转化一下就变成上面那道二叉苹果树了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <vector> using namespace std;int n, m, cn;int f[10009 ][1009 ], head[10009 ], to[10009 ], nxt[10009 ];void dp (int x) for (int i = head[x]; i; i = nxt[i]) { int y = to[i]; dp (y); for (int j = m + 1 ; j >= 1 ; j--) { for (int k = 0 ; k < j; k++) { f[x][j] = max (f[x][j], f[y][k] + f[x][j - k]); } } } } int main () scanf ("%d%d" , &n, &m); for (int i = 1 ; i <= n; i++) { int fa; scanf ("%d%d" , &fa, &f[i][1 ]); nxt[++cn] = head[fa]; to[cn] = i; head[fa] = cn; } dp (0 ); printf ("%d" , f[0 ][m + 1 ]); return 0 ; }
这道题和上道题在DP时(转移方程处)都不需要比较子树和 m 的大小是因为当 m 超出子树大小时,f f f
THEN NEXT!!!几乎 一模一样的题目:HDU-1561:The More,The Better 。
积蓄程度 给定一颗无向带权树,权值代表两点间流量的最大值,找一个节点作为根,向叶子节点流水(根节点的水流可以认为无限大),使整棵树的流水量最大。(建议自己读下acwing题面)
这道题的思路是 二次扫描 + 换根法 。d [ i ] d[i] d [ i ] i i i f [ i ] f[i] f [ i ] i i i d [ 4 ] d[4] d [ 4 ] d [ 1 ] d[1] d [ 1 ] f [ 1 ] f[1] f [ 1 ] m i n min m i n d [ 4 ] d[4] d [ 4 ] d [ i ] d[i] d [ i ] f [ i ] f[i] f [ i ] <= 换根法体现在这里
下面分别来讲讲两次扫描的具体过程
取一个点 DFS 一遍搜出所有的 d [ i ] d[i] d [ i ]
为了方便,我们这里取 1 号点开始DFS (记住这个 “ 为了方便 ” ) x x x j j j x x x ∗ (
*( ∗ ( d [ 2 ] d[2] d [ 2 ] ∞ \infty ∞ d [ 3 ] d[3] d [ 3 ] ∞ \infty ∞ d [ 5 ] d[5] d [ 5 ] ∞ \infty ∞
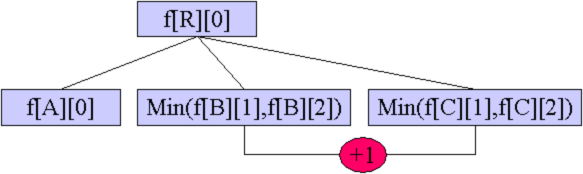
接下来,因为 d [ 3 ] d[3] d [ 3 ] 3,4 中通过 5 的流量;d [ 5 ] d[5] d [ 5 ] 5,4 中通过 10 的流量;d [ 4 ] d[4] d [ 4 ]
同理,因为 d [ 4 ] d[4] d [ 4 ] w [ 1 ] [ 4 ] w[1][4] w [ 1 ] [ 4 ] 1,4 中通过 13 的流量;d [ 2 ] d[2] d [ 2 ] 1,2 中通过 11 的流量;d [ 1 ] d[1] d [ 1 ] f [ 1 ] f[1] f [ 1 ] d [ 1 ] d[1] d [ 1 ]
如何判断叶子节点?
所以,第一次扫描的代码就能打出来了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int dfs_d ( int x, int fa ) if ( deg[x] == 1 ) { d[x] = 0x3f3f3f3f ; return d[x]; } d[x] = 0 ; for ( int i = head[x] ; i ; i = nxt[i] ) { int j = to[i]; if ( j == fa ) continue ; d[x] += min ( w[i], dfs_d ( j, x ) ); } return d[x]; }
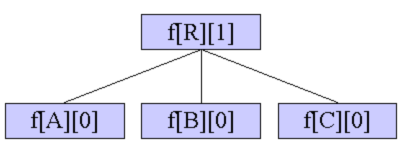
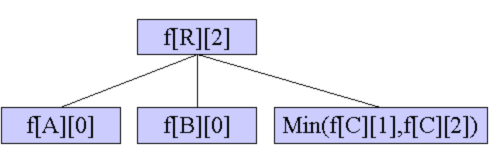
DP求出所有的 f [ i ] f[i] f [ i ]
d [ i ] d[i] d [ i ] f [ i ] f[i] f [ i ] f [ 1 ] f[1] f [ 1 ] f [ 4 ] f[4] f [ 4 ] 根 节点从 1 号点上换 到 4 号点上)。
要知道,除去 4 号点的子树以外的点到 1 号点(即原来的根节点)的总流量是如下部分(红框内):很显然 ,只要将 f [ 1 ] f[1] f [ 1 ] d [ 4 ] d[4] d [ 4 ] w [ 1 ] [ 4 ] w[1][4] w [ 1 ] [ 4 ] d [ 4 ] d[4] d [ 4 ] f [ 1 ] f[1] f [ 1 ] d [ 4 ] d[4] d [ 4 ] w [ 1 ] [ 4 ] w[1][4] w [ 1 ] [ 4 ] w [ 1 ] [ 4 ] w[1][4] w [ 1 ] [ 4 ] w [ 1 ] [ 4 ] w[1][4] w [ 1 ] [ 4 ] m i n min m i n x x x j j j f [ j ] = d [ j ] + min { f [ x ] − min { d [ j ] , w [ x ] [ j ] } , w [ x ] [ j ] } f[j]=d[j]+\min\{f[x]-\min\{d[j],w[x][j]\},w[x][j]\} f [ j ] = d [ j ] + min { f [ x ] − min { d [ j ] , w [ x ] [ j ] } , w [ x ] [ j ] }
然后,读者们就会发现这个式子并不适用于叶子结点,因为叶子结点的 d d d ∞ \infty ∞
f f f x x x j j j f [ j ] = min { w [ x ] [ j ] , f [ x ] − w [ x ] [ j ] } f[j]=\min\{w[x][j],f[x]-w[x][j]\} f [ j ] = min { w [ x ] [ j ] , f [ x ] − w [ x ] [ j ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void dfs_f (int x, int fa) for (int i = head[x]; i; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; if (deg[j] == 1 ) { f[j] = min (w[i], f[x] - w[i]); } else { f[j] = d[j] + min (f[x] - min (d[j], w[i]), w[i]); dfs_f (j, x); } } }
这样处理以后,恭喜你,得到了一个 90 分代码!!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <vector> using namespace std;const int N = 1000010 ;int T;int n, cn;int to[N], head[N], nxt[N], w[N], f[N], d[N], deg[N];void add (int a, int b, int c) nxt[++cn] = head[a]; to[cn] = b; w[cn] = c; head[a] = cn; } int dfs_d (int x, int fa) if (deg[x] == 1 ) { d[x] = 0x3f3f3f3f ; return d[x]; } d[x] = 0 ; for (int i = head[x]; i; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; d[x] += min (w[i], dfs_d (j, x)); } return d[x]; } void dfs_f (int x, int fa) for (int i = head[x]; i; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; if (deg[j] == 1 ) { f[j] = min (w[i], f[x] - w[i]); } else { f[j] = d[j] + min (f[x] - min (d[j], w[i]), w[i]); dfs_f (j, x); } } } int main () scanf ("%d" , &T); while (T--) { memset (head, 0 , sizeof head); memset (deg, 0 , sizeof deg); cn = 0 ; scanf ("%d" , &n); for (int i = 1 ; i < n; i++) { int x, y, z; scanf ("%d%d%d" , &x, &y, &z); add (x, y, z); add (y, x, z); deg[x]++; deg[y]++; } dfs_d (1 , -1 ); f[1 ] = d[1 ]; dfs_f (1 , -1 ); int res = 0 ; for (int i = 1 ; i <= n; i++)res = max (res, f[i]); printf ("%d\n" , res); } return 0 ; }
那么,还有一点错在哪儿呢?d f s _ d dfs\_d d f s _ d
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int dfs_d ( int x, int fa ) if ( deg[x] == 1 ) { d[x] = 0x3f3f3f3f ; return d[x]; } d[x] = 0 ; for ( int i = head[x] ; i ; i = nxt[i] ) { int j = to[i]; if ( j == fa ) continue ; d[x] += min ( w[i], dfs_d ( j, x ) ); } return d[x]; }
而且,我们在主函数中是将 1 号点看做根的。
为了方便,我们这里取 1 号点开始DFS
那如果 1 号点本身的度就只有一个呢?r o o t root r o o t n n n r o o t root r o o t r o o t root r o o t n n n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int root = n + 1 ; for (int i = 1 ; i <= n; i++) { if (deg[i] != 1 ) { root = i; break ; } } if (root > n) { printf ("%d\n" , w[1 ]); continue ; } dfs_d (root, -1 ); f[root] = d[root]; dfs_f (root, -1 );
如此一来,只要将主程序改一下就能得到满分程序啦!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 int main () scanf ("%d" , &T); while (T--) { memset (head, 0 , sizeof head); memset (deg, 0 , sizeof deg); cn = 0 ; scanf ("%d" , &n); for (int i = 1 ; i < n; i++) { int x, y, z; scanf ("%d%d%d" , &x, &y, &z); add (x, y, z); add (y, x, z); deg[x]++; deg[y]++; } int root = n + 1 ; for (int i = 1 ; i <= n; i++) { if (deg[i] != 1 ) { root = i; break ; } } if (root > n) { printf ("%d\n" , w[1 ]); continue ; } dfs_d (root, -1 ); f[root] = d[root]; dfs_f (root, -1 ); int res = 0 ; for (int i = 1 ; i <= n; i++)res = max (res, f[i]); printf ("%d\n" , res); } return 0 ; }
接下来再讲一题。
HDU-2196 : Computer 其实我都不知道这道题算不算换根法,毕竟我是只蒟蒻
给定一棵带权 树,求每个节点能到达的最远距离。
输入文件包含多组测试数据。n n n n n n
一行一个整数,第 i i i i i i
这题和上题很像,还是需要二次扫描和还根法。
第一次扫描:扫描出每个节点在以它为根的子树能到达的最大 距离和次大 距离,并标记出最大距离经过了该节点的哪个儿子节点。
第二次扫描:求出每个节点通过它的父节点能到达的最大距离。
接下来详细讲讲两次扫描如何进行。
第一次扫描的过程和求树的直径很像。
求树的直径:f [ i ] [ 0 ] f[i][0] f [ i ] [ 0 ] i i i i i i f [ i ] [ 1 ] f[i][1] f [ i ] [ 1 ] i i i i i i j j j x x x w [ j ] [ x ] w[j][x] w [ j ] [ x ] j j j x x x
1 2 3 4 5 6 7 8 9 if ( f[x][0 ] < f[j][0 ] + w[j][x] ) { f[x][1 ]=f[i][0 ]; f[x][0 ]=f[j][0 ]+w[j][x]; } else if ( f[x][1 ] < f[j][0 ] + w[j][x] ){ f[x][1 ]=f[j][0 ]+w[j][x]; }
怎么样是不是很像?其实是我懒
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int dfs1 (int x, int fa) if (f[x][0 ] != 0x3f3f3f3f )return f[x][0 ]; f[x][0 ] = f[x][1 ] = f[x][2 ] = v[x] = 0 ; for (int i = head[x]; i; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; if (f[x][0 ] < dfs1 (j, x) + w[i]) { v[x] = j; f[x][1 ] = f[x][0 ]; f[x][0 ] = f[j][0 ] + w[i]; } else if (f[x][1 ] < f[j][0 ] + w[i]) { f[x][1 ] = f[j][0 ] + w[i]; } } return f[x][0 ]; }
OK,接下来是第二次扫描。
设 f [ i ] [ 2 ] f[i][2] f [ i ] [ 2 ] i i i
此时有两种情况:父节点的最大距离经过此节点,则此点的 f [ i ] [ 2 ] f[i][2] f [ i ] [ 2 ] j j j x x x f [ i ] [ 2 ] = max { f [ x ] [ 2 ] , f [ x ] [ 1 ] } f[i][2]=\max\{f[x][2],f[x][1]\} f [ i ] [ 2 ] = max { f [ x ] [ 2 ] , f [ x ] [ 1 ] } f [ i ] [ 2 ] f[i][2] f [ i ] [ 2 ] f [ i ] [ 2 ] = max { f [ x ] [ 2 ] , f [ x ] [ 0 ] } f[i][2]=\max\{f[x][2],f[x][0]\} f [ i ] [ 2 ] = max { f [ x ] [ 2 ] , f [ x ] [ 0 ] } 很容易 地打出来了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void dfs2 (int x, int fa) for (int i = head[x]; i; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; if (j == v[x]) { f[j][2 ] = max (f[x][2 ], f[x][1 ]) + w[i]; } else { f[j][2 ] = max (f[x][2 ], f[x][0 ]) + w[i]; } dfs2 (j, x); } }
通篇代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <cmath> using namespace std;const int N = 100010 ;int n, x, y, cn;int head[N], to[N], nxt[N], w[N], f[N][3 ], v[N];void add (int a, int b, int c) nxt[++cn] = head[a]; to[cn] = b; w[cn] = c; head[a] = cn; } int dfs1 (int x, int fa) if (f[x][0 ] != 0x3f3f3f3f )return f[x][0 ]; f[x][0 ] = f[x][1 ] = f[x][2 ] = v[x] = 0 ; for (int i = head[x]; i; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; if (f[x][0 ] < dfs1 (j, x) + w[i]) { v[x] = j; f[x][1 ] = f[x][0 ]; f[x][0 ] = f[j][0 ] + w[i]; } else if (f[x][1 ] < f[j][0 ] + w[i]) { f[x][1 ] = f[j][0 ] + w[i]; } } return f[x][0 ]; } void dfs2 (int x, int fa) for (int i = head[x]; i; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; if (j == v[x]) { f[j][2 ] = max (f[x][2 ], f[x][1 ]) + w[i]; } else { f[j][2 ] = max (f[x][2 ], f[x][0 ]) + w[i]; } dfs2 (j, x); } } int main () while (scanf ("%d" , &n) == 1 && n) { memset (f, 0x3f , sizeof f); memset (head, 0 , sizeof head); memset (v, 0 , sizeof v); cn = 0 ; for (int i = 2 ; i <= n; i++) { scanf ("%d%d" , &x, &y); add (i, x, y); add (x, i, y); } dfs1 (1 , 0 ); dfs2 (1 , 0 ); for (int i = 1 ; i <= n; i++) { printf ("%d\n" , max (f[i][0 ], f[i][2 ])); } } return 0 ; }
OK,我们的换根法就讲完啦!
接下来的又是一些例题。
POJ-1655:Balancing Act 因为是英文题面,我这里题目描述就写详细一点好了。
给定一棵无权树。将一个节点的 Balance 定义为从该树中删除该节点所创建的森林中最大的树的大小。
输入文件的第一行包含一个整数 t(1 <= t <= 20),即测试样例的数量。每个测试样例的第一行包含一个整数 N(1 <= N <= 20,000),即节点的数量。接下来的 N-1行,每行两个节点编号,表示一条边的两个端点。没有一条边会被列出两次。
对于每个测试样例,输出一行包含两个整数,即具有最小Balance的节点编号和对应的Balance值。
不是我说,但是这是真的水 而且这题也很水 f [ i ] f[i] f [ i ] i i i s o n [ i ] son[i] s o n [ i ] i i i j j j x x x s o n [ x ] = ∑ j j ∈ x s o n [ j ] + 1 son[x]=\sum_{j}^{j \in x} son[j]+1 s o n [ x ] = ∑ j j ∈ x s o n [ j ] + 1 s o n [ x ] son[x] s o n [ x ] s o n son s o n
接下来是 f f f f [ x ] f[x] f [ x ] x x x x x x f [ x ] f[x] f [ x ] f [ x ] f[x] f [ x ] f [ x ] = max { f [ x ] , s o n [ j ] } ( j ∈ x ) f[x]=\max \{f[x],son[j]\}(j \in x) f [ x ] = max { f [ x ] , s o n [ j ] } ( j ∈ x ) f [ x ] = max { f [ x ] , n − s o n [ x ] } f[x]=\max \{f[x],n-son[x]\} f [ x ] = max { f [ x ] , n − s o n [ x ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <cmath> using namespace std;const int N = 1000010 ;int n, x, y, cn;int head[N], nxt[N], to[N], f[N], son[N];void add (int a, int b) nxt[++cn] = head[a]; to[cn] = b; head[a] = cn; } int dfs (int x, int fa) for (int i = head[x]; i; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; son[x] += dfs (j, x); f[x] = max (f[x], son[j]); } f[x] = max (n - son[x], f[x]); return son[x]; } int main () int T; scanf ("%d" , &T); while (T--) { memset (head, 0 , sizeof head); memset (f, 0 , sizeof f); cn = 0 ; scanf ("%d" , &n); for (int i = 1 ; i < n; i++) { scanf ("%d%d" , &x, &y); add (x, y); add (y, x); son[i] = 1 ; } son[n] = 1 ; if (n == 1 ) { printf ("1 0\n" ); continue ; } dfs (1 , -1 ); int minn = 0x3f3f3f3f , k; for (int i = 1 ; i <= n; i++) { if (f[i] < minn) { minn = f[i]; k = i; } } printf ("%d %d\n" , k, minn); } return 0 ; }
水题讲完啦 POJ-3107:Godfather (就好像 选课 和 The More,The Better 的区别)。
ZOJ-3201:Tree of Tree 一道水题。
给你一棵带权树,找出节点数在 K 内的最大子树。
多组测试样例。
每个样例一行输出,表示最大权值的子树的权值和。
又一道树上背包,而且比前面的简单多了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <vector> using namespace std;const int N = 110 ;int n, m;int f[N][110 ];vector < int > son[N]; void dfs (int x, int fa) for (int i = 0 ; i < son[x].size (); i++) { int j = son[x][i]; if (j == fa)continue ; dfs (j, x); for (int p = m; p > 0 ; p--) { for (int k = 0 ; k < p; k++) { f[x][p] = max (f[x][p], f[x][p - k] + f[j][k]); } } } } int main () while (scanf ("%d%d" , &n, &m) != EOF) { memset (f, -1 , sizeof f); for (int i = 0 ; i < n; i++) { son[i].clear (); } for (int i = 0 ; i < n; i++)scanf ("%d" , &f[i][1 ]); for (int i = 1 ; i < n; i++) { int x, y; scanf ("%d%d" , &x, &y); son[x].push_back (y); son[y].push_back (x); } dfs (0 , -1 ); int ans = -1 ; for (int i = 0 ; i < n; i++) { ans = max (ans, f[i][m]); } printf ("%d\n" , ans); } return 0 ; }
I AM SO WATERY!!!
POJ-2378 跟 POJ-1655:Balancing Act 一样,只要在最后输出时判断一下最大值有没有超过 n/2 就好了,如果没超过就直接输出。留给读者做习题好了 。
洛谷P1272:重建道路 终于有一道不是那么水的题啦!
给定一棵无权树,求出至少要删多少条边才能得到一棵节点数为 m 的子树。
也是一道树上背包的题目。f [ i ] [ j ] f[i][j] f [ i ] [ j ] i i i j j j f [ i ] [ 1 ] f[i][1] f [ i ] [ 1 ] i i i f [ 2 ] [ 1 ] f[2][1] f [ 2 ] [ 1 ] m m m j j j x x x f [ x ] [ p ] = min { f [ x ] [ p ] , f [ x ] [ p − k ] + f [ j ] [ k ] − 2 } , ( 1 < = p < = m , 1 < = k < = p ) f[x][p]=\min\{f[x][p],f[x][p-k]+f[j][k]-2\},(1<=p<=m,1<=k<=p) f [ x ] [ p ] = min { f [ x ] [ p ] , f [ x ] [ p − k ] + f [ j ] [ k ] − 2 } , ( 1 < = p < = m , 1 < = k < = p ) -2 是什么意思呢?f [ x ] [ p ] = min { f [ x ] [ p ] , ( f [ x ] [ p − k ] − 1 ) + ( f [ j ] [ k ] − 1 ) } , ( 1 < = p < = m , 1 < = k < = p ) f[x][p]=\min\{f[x][p],(f[x][p-k]-1)+(f[j][k]-1)\},(1<=p<=m,1<=k<=p) f [ x ] [ p ] = min { f [ x ] [ p ] , ( f [ x ] [ p − k ] − 1 ) + ( f [ j ] [ k ] − 1 ) } , ( 1 < = p < = m , 1 < = k < = p ) -1 是什么意思呢?f f f 去掉 的边,如在此图中, f [ 2 ] f[2] f [ 2 ] f [ 3 ] f[3] f [ 3 ] -1 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <iostream> #include <cstring> #include <algorithm> #include <cstdio> using namespace std;const int N = 400 ;int n, m, cn, x, y;int nxt[N], f[N][N], to[N], head[N], a[N], num[N], ans = 0x3f3f3f3f ;void add (int x, int y) to[++cn] = y; nxt[cn] = head[x]; head[x] = cn; num[x]++; } int dfs (int x, int fa) f[x][1 ] = num[x]; for (int i = head[x]; i; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; dfs (to[i], x); for (int p = m; p >= 1 ; p--) { for (int k = 1 ; k <= p; k++) { f[x][p] = min (f[x][p], f[x][p - k] + f[j][k] - 2 ); } } } return ans = min (ans, f[x][m]); } int main () scanf ("%d%d" , &n, &m); memset (f, 0x3f , sizeof (f)); for (int i = 1 ; i < n; i++) { scanf ("%d%d" , &x, &y); add (x, y); add (y, x); } printf ("%d" , dfs (1 , 0 )); return 0 ; }
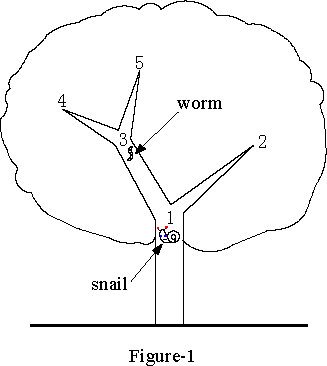
POJ-2057:The Lost House 给定一棵树,节点数 n <= 1000(每个节点的分支 <= 8),一只蜗牛在根(1 号节点)处,他要到叶子节点上去找房子,而有几个节点上(根节点上没有)有虫子告诉你房子在不在这棵子树上,求出蜗牛最快找到房子的路径的期望值。
多组样例。a a a b b b i i i x x x i i i x x x b b b i i i i i i
对于每个样例,输出一行包含一个四位小数的浮点数,表示最小的期望值。
首先,啥是期望值?
百度百科定义如下:
数学期望(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。它反映随机变量平均取值的大小。
在这题中可以把它理解成加权平均值。(两者不一样,只是这题较特殊)(其实我到现在都不是很明白期望值是个什么东西)
说不明白,举个例子吧。
他可以先去 2 号点。如果他在那里找不到房子,他应该回到 1 号点,然后通过3号点到达 4(或5)号点。如果还是不行,他就得返回3点,然后去5点(或4点),在那里他无疑会找到房子。在这个选择中,蜗牛所走的距离为 1、4、6,分别对应于房子在2、4(或5)、5(或4)点的情况。所以期望值是(1+4+6)/3=11/3。
显然,这种策略并没有充分利用虫子给的的信息。如果蜗牛先去3号点,从蠕虫那里得到有用的信息,然后选择回到 1 号点,然后去 2 号点,或者去 4 号或 5 号点碰碰运气,那么他所走的距离将是 2、3、4,对应于房子的不同位置。在这样的策略中,数学期望值将是(2+3+4)/3=3,而这正是蜗牛应该在树上搜寻的路线。
接下来,直入主题 。f [ i ] [ 0 ] f[i][0] f [ i ] [ 0 ] i i i 没有找到 房子的步数的总和;f [ i ] [ 1 ] f[i][1] f [ i ] [ 1 ] i i i 找到 房子的步数的总和;l e a [ i ] lea[i] l e a [ i ] i i i b u g [ i ] bug[i] b u g [ i ] i i i
设 Pi 为房子在 i i i x x x y y y x x x y y y f [ x ] [ 1 ] ∗ P x + ( f [ x ] [ 0 ] + 2 + f [ y ] [ 1 ] ) ∗ P y f[x][1] * P~x~+(f[x][0]+2+f[y][1]) * P~y~ f [ x ] [ 1 ] ∗ P x + ( f [ x ] [ 0 ] + 2 + f [ y ] [ 1 ] ) ∗ P y y y y x x x f [ y ] [ 1 ] ∗ P y + ( f [ y ] [ 0 ] + 2 + f [ x ] [ 1 ] ) ∗ P x f[y][1] * P~y~+(f[y][0]+2+f[x][1]) * P~x~ f [ y ] [ 1 ] ∗ P y + ( f [ y ] [ 0 ] + 2 + f [ x ] [ 1 ] ) ∗ P x (就是懒呗) ( f [ x ] [ 0 ] + 2 ) ∗ P y 和 ( f [ y ] [ 0 ] + 2 ) ∗ P x (f[x][0]+2) * P~y~ 和 (f[y][0]+2) * P~x~ ( f [ x ] [ 0 ] + 2 ) ∗ P y 和 ( f [ y ] [ 0 ] + 2 ) ∗ P x +2 是连接该子树的边的来回两次。
然后来推转移方程。j j j x x x f [ x ] [ 0 ] = ∑ { f [ j ] [ 0 ] + 2 } ( 前提是此时 b u g [ x ] = 0 ,即此处没有虫子 ) f[x][0]=\sum\{f[j][0]+2\}(前提是此时bug[x]=0,即此处没有虫子) f [ x ] [ 0 ] = ∑ { f [ j ] [ 0 ] + 2 } ( 前 提 是 此 时 b u g [ x ] = 0 , 即 此 处 没 有 虫 子 ) b u g [ x ] bug[x] b u g [ x ] f [ x ] [ 0 ] f[x][0] f [ x ] [ 0 ] f [ x ] [ 0 ] = f [ x ] [ 1 ] = 0 f[x][0]=f[x][1]=0 f [ x ] [ 0 ] = f [ x ] [ 1 ] = 0 f [ x ] [ 1 ] + = f [ x ] [ 0 ] ∗ l e a [ q [ x ] [ i ] ] + f [ q [ x ] [ i ] ] [ 1 ] + l e a [ q [ x ] [ i ] ] f[x][1] += f[x][0] * lea[q[x][i]] + f[q[x][i]][1] + lea[q[x][i]] f [ x ] [ 1 ] + = f [ x ] [ 0 ] ∗ l e a [ q [ x ] [ i ] ] + f [ q [ x ] [ i ] ] [ 1 ] + l e a [ q [ x ] [ i ] ] q q q x x x f [ x ] [ 1 ] + = ( f [ x ] [ 0 ] + 1 ) ∗ l e a [ q [ x ] [ i ] ] + f [ q [ x ] [ i ] ] [ 1 ] f[x][1] += (f[x][0]+1) * lea[q[x][i]] + f[q[x][i]][1] f [ x ] [ 1 ] + = ( f [ x ] [ 0 ] + 1 ) ∗ l e a [ q [ x ] [ i ] ] + f [ q [ x ] [ i ] ] [ 1 ] f [ x ] [ 0 ] f[x][0] f [ x ] [ 0 ] f [ x ] [ 1 ] f[x][1] f [ x ] [ 1 ] +1 后乘上 该子树的叶子节点数 再加上找到房子的路径长度就行了。
这种大家还是自己画个图推一下比较好 (我又懒又菜,只能水一下了)
然后就水完了 此博客
下面是代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <iostream> #include <cstdio> #include <algorithm> #include <cstring> #include <vector> using namespace std;const int N = 1010 ;int n, a;char b[5 ];vector <int > q[N]; int f[N][2 ], bug[N], lea[N];bool cmp (int x, int y) return (f[x][0 ] + 2 ) * lea[y] < (f[y][0 ] + 2 ) * lea[x]; } void dfs (int x) int len = q[x].size (); if (len == 0 ) { f[x][0 ] = 0 ; f[x][1 ] = 0 ; lea[x] = 1 ; return ; } for (int i = 0 ; i < len; i++) dfs (q[x][i]); for (int i = 0 ; i < len; i++) lea[x] += lea[q[x][i]]; sort (q[x].begin (), q[x].end (), cmp); for (int i = 0 ; i < len; i++) { f[x][1 ] += f[x][0 ] * lea[q[x][i]] + f[q[x][i]][1 ] + lea[q[x][i]]; f[x][0 ] += f[q[x][i]][0 ] + 2 ; } if (bug[x]) { f[x][0 ] = 0 ; } } int main () while (scanf ("%d" , &n) && n) { memset (f, 0 , sizeof f); memset (bug, 0 , sizeof bug); memset (lea, 0 , sizeof lea); for (int i = 1 ; i <= n; i++)q[i].clear (); scanf ("%d%s" , &a, b); for (int i = 2 ; i <= n; i++) { scanf ("%d%s" , &a, b); if (b[0 ] == 'Y' )bug[i] = 1 ; q[a].push_back (i); } dfs (1 ); printf ("%.4lf\n" , 1.0 * f[1 ][1 ] / lea[1 ]); } return 0 ; }
这题挺不错的,但我讲的不怎么好,敬请谅解,毕竟我是只蒟蒻。
下一题。
POJ-1848:Tree 给定一棵树,求最少连多少条边,使得每个点在且仅在某一个环内。(一个环至少三个点)
这道题挺好的 (整了我好久) 参考博客
设 f [ x ] [ 0 ] f[x][0] f [ x ] [ 0 ] x x x
设 f [ x ] [ 1 ] f[x][1] f [ x ] [ 1 ] x x x
设 f [ x ] [ 2 ] f[x][2] f [ x ] [ 2 ] x x x
状态有了,怎么转移呢?
根R的所有子树自己解决(取状态0),转移到R的状态1。即R所有的儿子都变成每个顶点恰好在一个环中的图,R自己不变。
即 f [ x ] [ 1 ] f[x][1] f [ x ] [ 1 ] f [ s o n ] [ 0 ] f[son][0] f [ s o n ] [ 0 ]
根R的k-1个棵树自己解决,剩下一棵子树取状态1和状态2的最小值,转移到R的状态2。剩下的那棵子树和根R就构成了长度至少为2的一条链。
让其中一个子节点(或与子节点相连的链)与根节点构成一条链。
根R的k-2棵子树自己解决,剩下两棵子树取状态1和状态2的最小值,在这两棵子树之间连一条边,转移到R的状态0。
让其中两个子节点(或者与子节点相连的链)与根节点组成一个环(因为一个环至少有三个节点)。
根R的k-1棵子树自己解决,剩下一棵子树取状态2(子树里还剩下长度至少为2的一条链),在这棵子树和根之间连一条边,构成一个环,转移到R的状态0。
让其中一个子节点(或与子节点相连的一条链)加上根节点再加一条边组成一个环。
那么转移方程怎么写呢?s u m sum s u m x x x f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ] j j j x x x m i n 1 min1 m i n 1 f [ j ] [ 1 ] f[j][1] f [ j ] [ 1 ] f [ j ] [ 2 ] f[j][2] f [ j ] [ 2 ] f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ] m i n 2 min2 m i n 2 f [ j ] [ 1 ] f[j][1] f [ j ] [ 1 ] f [ j ] [ 2 ] f[j][2] f [ j ] [ 2 ] f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ] j j j m i n 1 min1 m i n 1 m i n 3 min3 m i n 3 f [ j ] [ 2 ] f[j][2] f [ j ] [ 2 ] f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ]
为啥要减去 f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ] s u m sum s u m f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ] f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ] f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ] m i n 1 、 m i n 2 min1、min2 m i n 1 、 m i n 2 f [ j ] [ 1 ] f[j][1] f [ j ] [ 1 ] f [ j ] [ 2 ] f[j][2] f [ j ] [ 2 ] f [ j ] [ 1 ] f[j][1] f [ j ] [ 1 ] f [ j ] [ 2 ] f[j][2] f [ j ] [ 2 ] f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ]
当 x x x s u m sum s u m m i n 1 min1 m i n 1 m i n 2 min2 m i n 2 m i n 3 min3 m i n 3 f [ x ] [ 1 ] = s u m f[x][1]=sum f [ x ] [ 1 ] = s u m f [ x ] [ 2 ] = s u m + m i n 1 f[x][2]=sum+min1 f [ x ] [ 2 ] = s u m + m i n 1 m i n 1 、 m i n 2 min1、min2 m i n 1 、 m i n 2 f [ j ] [ 0 ] f[j][0] f [ j ] [ 0 ] f [ x ] [ 0 ] f[x][0] f [ x ] [ 0 ] f [ x ] [ 0 ] = s u m + 1 + min ( m i n 1 + m i n 2 , m i n 3 ) f[x][0]=sum+1+\min(min1+min2 , min3) f [ x ] [ 0 ] = s u m + 1 + min ( m i n 1 + m i n 2 , m i n 3 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <queue> using namespace std;const int inf = 0x3f3f3f3f ;const int N = 1100 ;int head[N], to[N], nxt[N], f[N][3 ];int n, cn;void add (int a, int b) nxt[++cn] = head[a]; to[cn] = b; head[a] = cn; } void dfs (int x, int fa) int sum = 0 , min1 = inf, min2 = inf, min3 = inf; for (int i = head[x]; i != -1 ; i = nxt[i]) { int j = to[i]; if (j == fa)continue ; dfs (j, x); sum += f[j][0 ]; min3 = min (min3, f[j][2 ] - f[j][0 ]); if (min (f[j][2 ] - f[j][0 ], f[j][1 ] - f[j][0 ]) < min1) { min2 = min1; min1 = min (f[j][2 ] - f[j][0 ], f[j][1 ] - f[j][0 ]); } else if (min (f[j][2 ] - f[j][0 ], f[j][1 ] - f[j][0 ]) < min2) { min2 = min (f[j][2 ] - f[j][0 ], f[j][1 ] - f[j][0 ]); } } f[x][1 ] = sum; f[x][2 ] = sum + min1; f[x][0 ] = sum + 1 + min (min1 + min2, min3); } int main () while (scanf ("%d" , &n) != EOF) { memset (head, -1 , sizeof head); memset (f, 0 , sizeof f); cn = 0 ; for (int i = 1 ; i < n; i++) { int x, y; scanf ("%d%d" , &x, &y); add (x, y); add (y, x); } dfs (1 , -1 ); printf ("%d\n" , f[1 ][0 ] >= inf ? -1 : f[1 ][0 ]); } return 0 ; }
接下来是今天的最后一题。
POJ-2152:Fire 在一棵树形的城市群中建立一些消防站(每个城市中建立消防站所需的花费不同),但每个城市有一个到消防站的最大距离限制,求需要的最小花费。
多组测试数据。
每族第一行一个整数 N,表示有几座城市。
每组数据输出一行,表示最小的花费。
这题好难啊 (下辈子) 再来补吧。
OK