一只蒟蒻的树形DP学习笔记
START MY SHOW!!!!
# 为什么叫树形DP?与线性DP有什么区别?
两者的本质一致,只不过是在处理数据时的迭代方式不同了而已。
即,数据间迭代关系由线性(线性DP)变成了非线性(树形DP)。
举个栗子,如下两题:
最大子段和和最大子树和
前者是 给出一个长度为 n 的序列 a,选出其中连续且非空的一段使得这段和最大。
后者是 给出一个节点数为 n 的树 a,选出其中几个连续节点(包括根节点)的非空集合使得这段和最大。
两者的思想一模一样,只有迭代的方式不一样。
甚至可以说,前者也只是后者的一种特殊情况。
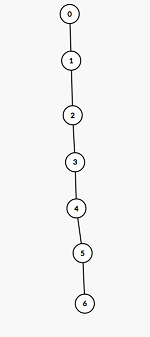
如左侧为一棵树(最大子树和的情况),而右侧则是一棵退化的树(最大子段和的情况)。

所以,不能把树形DP当做单独的一种算法来学(话说DP好像本来就算不上是算法)。
# 树形DP的几个经典应用
# 树的直径
# 定义
一棵树中两个节点之间的最远距离。
# 求解
如果单纯地讨论这个问题,可以通过跑两次DFS实现,后面有讲找所有点能到的最远距离,这里就不多讲了。
附:DFS法求树的直径
那么怎么通过树形DP解决该问题呢?
设 $f1[i]$ 为以 $i$ 节点为根节点的子树中, $i$ 到叶子节点的最大距离;
设 $f2[i]$ 为以 $i$ 节点为根节点的子树中, $i$ 到叶子节点的次大(第二大)距离。
令 $son$ 为 $i$ 的儿子
设 $w[i][son]$ 为 $son$ 到 $i$ 的路径长度
下面用代码解释:1
2
3
4
5
6
7
8
9if( f1[i] < f1[son] + w[i][son] )
{//如果i节点到叶节点的最大距离 小于 son节点到叶节点的最大距离 加上 i节点到son节点的距离
f2[i]=f1[i];//将i节点到叶节点的最大值变成次大值
f1[i]=f1[son]+w[i][son];//更新最大值
}
else if( f2[i] < f1[son] + w[i][son] )
{//如果i的最大值大于son的,但i的次大值小于son
f2[i]=f1[son]+w[i][son];//更新次大值
}
最后的直径则是 $(f1[i]+f2[i])$ 的最大值。
如果是邻接表的话则是:1
2
3
4
5
6
7
8
9
10
11void dp(int x)
{
v[x]=1; //v 数组记录点是否被走过
for(int i = head[x]; i; i = nxt[i]){
int j = to[i];
if(v[j]) continue; //如果点做走过则跳过
dp(j);
ans = max(ans, d[x] + d[j] + w[i]);
d[x] = max(d[x], d[j] + w[i]);
}
}
最后直径就是 ans 的值。
OK,NEXT!!!
# 树的重心
# 定义
找一个点,使其所有子树中的最大子树节点数最少(或从此点将树分成两半,分成的两棵树权值差最小),该点即为该树的重心。
# 求解
可用DFS求解
同样地,附上链接:
DFS法求树的重心
# 例题:
# 题目描述
给定一棵带权二叉树,相邻两节点之间距离为 1 ,求出该树的重心,使每个点到重心的距离与点的权值的乘积 的总和 最小。
# 题解
设 $f[i]$ 为以 $i$ 为根的的总距离, $size[i]$ 为以 $i$ 为根的子树大小(“ 大小 ” 指的是带权的大小)显然,
$ans = min { f[i] , 1 <= i <= n }$
那么,我们只要DFS求出任意一个点的 $f$ ,再通过转移方程求出所有的 $f$ 就好了
为了方便,我们先DFS求出 $f[1]$ 。
转移方程如下,对于每个 $i$ 可到达的 $j$ 点( $j$ 为 $i$ 的儿子):
$f[j] = f[i] + size[1] − size[j] − size[j]$
当我们从 $i$ 点转移到 $j$ 点时(即根从 $i$ 变为 $j$ 时),每个 $j$ 的子树的节点到根的距离都减 1 。本来 $j$ 的子树的节点应该到 $i$ 这个节点,但因为根节点下移一个,所以距离全部减 1 (- $size[j]$)。
同理,在根节点上方的节点到根节点的距离都加上 1 , 总路程就加了($size[1]$ − $size[j]$)。
$size[1]$ 即为整棵树的大小, $size[j]$则是除了 $j$ 节点的子树以外的节点数。
参考博客
# 代码
这篇代码是蛮早写的,码风和后面不一致,敬请谅解。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
using namespace std;
int n,a,b,l,r,cn;
int dd[10000],f[100000],to[10000],next[10000],head[10000],w[10000];
//这里的 dd 数组就是 size 数组
int ans=0x3f3f3f3f;
int dfs( int u , int fa , int dep )
{
dd[u] = w[u];
for( int i = head[u] ; i ; i = next[i] ) //邻接表储存
{
if( to[i] != fa )
{ //如果该点不是叶子节点
dfs( to[i] , u , dep+1 ); //继续向下搜
dd[u] += dd[to[i]];
}
}
f[1] += w[u] * dep;
}
int dp( int u , int fa )
{
for( int i = head[u] ; i ; i = next[i] )
{
if( to[i] != fa )
{
f[to[i]] = f[u] + dd[1] - dd[to[i]]*2;
dp( to[i] , u );
}
}
ans = min( ans , f[u] );
}
int main()
{
scanf("%d",&n);
for( int i = 1 ; i <= n ; i ++ )
{
scanf("%d%d%d", &w[i] , &l , &r);
if( l )
{
to[++cn] = l;
next[cn] = head[i];
head[i] = cn;
to[++cn] = i;
next[cn] = head[l];
head[l] = cn;
}
if( r )
{
to[++cn] = r;
next[cn] = head[i];
head[i] = cn;
to[++cn] = i;
next[cn] = head[r];
head[r] = cn;
}
}
dfs( 1 , 0 , 0 );
dp( 1 , 0 );
printf("%d",ans);
return 0;
}
这里还有道进阶的题目 (就当做习题好了)。
题解的话,我有时间写。。。吧
题目:POJ-3140:Contestants Division
OK,MOVING ON!!!
# 最大子树
# 例题:
# 题目描述
给出一个节点数为 n 的树 a,选出其中几个连续节点(包括根节点)的非空集合使得这段和最大。
# 题解
前面说了树形DP与线性DP思想一致,在这题上就能得到充分体现。
首先,每个点有两种状态:取或不取。
开一个vector来存储每一个节点的儿子。
设 $f[i][1]$ 为以 $i$ 为根的最大子树和(取根节点),$f[i][0]$ 为以 $i$ 为根的最大子树和(不取根节点)
那么,转移方程就出来了:
$f[i][1]+=max { f[son][1] , f[son][0] }$
$f[i][1]$ 每次加上自己儿子取或不取中大的一个(因为权值可能有负数,所以有时不取会比去了大)。
附上代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
using namespace std;
int n, x, y;
int a[17000], v[17000], f[17000][2];
vector < int > son[17000];
void find(int root)
{
f[root][1] = a[root];
f[root][0] = 0;
for (int i = 0; i < son[root].size(); i++)
{
int y = son[root][i];
find(y);
f[root][1] += max(f[y][1], f[y][0]);
}
}
int main()
{
scanf("%d", &n);
for (int i = 1; i <= n; i++)
{
scanf("%d", &a[i]);
}
for (int i = 1; i < n; i++)
{
scanf("%d%d", &x, &y);
son[y].push_back(x);
v[x] = 1;
}
for (int i = 1; i <= n; i++)
{
if (!v[i])
{
find(i);
printf("%d", max(f[i][0], f[i][1]));
}
}
return 0;
}
仔细观察发现, $f[i][0]$ 不论如何都是 0 ,所以可以对上面的代码进行优化,把 $f[i][0]$ 直接改成 0 ,不必再更新。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
using namespace std;
int n, x, y;
int a[17000], v[17000], f[17000];
vector < int > son[17000];
void find(int root)
{
f[root] = a[root];
for (int i = 0; i < son[root].size(); i++)
{
int y = son[root][i];
find(y);
f[root] += max(f[y], 0);
}
}
int main()
{
scanf("%d", &n);
for (int i = 1; i <= n; i++)
{
scanf("%d", &a[i]);
}
for (int i = 1; i < n; i++)
{
scanf("%d%d", &x, &y);
son[y].push_back(x);
v[x] = 1;
}
for (int i = 1; i <= n; i++)
{
if (!v[i])
{
find(i);
printf("%d", f[i]);
}
}
return 0;
}
ALRIGHT,MOVING ON!!
#
经典老题
# 题目描述
给出一棵带权树,要求相邻的两点不能同时取,求能取到的最大权值和。
# 题解
同样地,每个点有两种状态,取或不取。
开一个vector来存储每一个节点的儿子。
我们设 $f[i][1]$ 为取根节点时子树取到的最大值, $f[i][0]$ 为不取根节点时子树取到的最大值。
有没有发现这道题和最大子树和非常像? 唯一的区别就是后者比前者多了一个约束条件:相邻的两个点不能同时取。
那么,我们只要将原来的代码稍作改动即可。
即将转移方程改为:
$ f[i][1] += f[son][0] ; $
$f[i][0] += max { f[son][1] , f[son][0] } ;$
当取根节点时,它的儿子节点只能不取; 当不取根节点时,它的儿子节点可以选择取或不取。
下面附上代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
using namespace std;
int n;
vector < int > son[10000];
int f[10000][2], v[10000], h[10000];
void find(int x)
{
f[x][1] = h[x];
f[x][0] = 0;
for (int i = 0; i < son[x].size(); i++)
{
int y = son[x][i];
find(y);
f[x][1] += f[y][0];
f[x][0] += max(f[y][1], f[y][0]); //区别在这里
}
}
int main()
{
scanf("%d", &n);
for (int i = 1; i <= n; i++)
{
scanf("%d", &h[i]);
}
for (int i = 1; i < n; i++)
{
int x, y;
scanf("%d%d", &x, &y);
son[y].push_back(x);
v[x] = 1;
}
for (int i = 1; i <= n; i++)
{
if (!v[i])
{
find(i);
printf("%d", max(f[i][1], f[i][0]));
break;
}
}
return 0;
}
NEEEEEEEEEXT!!!
#
这也是道经典题目。
做过树形DP的肯定做过这道和上一道题。
# 题目描述
给定一棵带权二叉树,要求减掉几条枝,求保留 $m$ 条枝能保留的最大权值和。
# 题解
设 $f[i][j]$ 为以 $i$ 为根节点的子树 取 $j$ 条枝 的最大权值和。
这道题可以看做是树上的01背包:
$m$ 即为背包容量,每条边的体积为 1 ,价值为点的权值
下面在代码中解释
# 代码及解释
1 |
|
OK,基础应用讲的差不多了,接下来看几题例题。
# 应用升级
# 树上背包
# 例题:
又一题经典老题 (比本蒟蒻还大10岁)
# 题目描述
一个背包,容量为 M ,物品总数为 N ,每个物品体积为 1 ,价值为 $s[i]$ ,有一些物品需要在其他物品选择后才能选(即要选此物品必须先选另一个物品),求装满背包能得到的最大价值。
# 题解
这道题其实稍微转化一下就变成上面那道二叉苹果树了。
两者区别在于,上题是一棵树,而这题是森林。
其实,只要将 0 号节点 设为森林中的每一棵树的根节点的父节点,那么,就将这一片森林转化成一棵树了。
同时,因为加了一个 0 号节点,所以要将 M 加一。
其他基本与上题一致,具体在代码中解释1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
using namespace std;
int n, m, cn;
int f[10009][1009], head[10009], to[10009], nxt[10009];
void dp(int x)
{
for (int i = head[x]; i; i = nxt[i])
{
int y = to[i];
dp(y);
for (int j = m + 1; j >= 1; j--)
{//因为加了 0 节点,所以 m+1
for (int k = 0; k < j; k++)
{//k不能取 j 是因为要去掉该子树的根节点
f[x][j] = max(f[x][j], f[y][k] + f[x][j - k]);
//这里 j-k 不需要减一是因为这道题取的是点而不是边,所以最多只需要减一个点。
}
}
}
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++)
{
int fa;
scanf("%d%d", &fa, &f[i][1]);
nxt[++cn] = head[fa];
to[cn] = i;
head[fa] = cn;
}
dp(0);
printf("%d", f[0][m + 1]);
return 0;
}
这道题和上道题在DP时(转移方程处)都不需要比较子树和 m 的大小是因为当 m 超出子树大小时,$f$ 数组中储存的数为 0 ,因为这两道题的数据都不可能小于 0 ,所以 0 一定不会成为最大值,也就不会影响结果。
THEN NEXT!!!
福利(做一题赚一题):一道几乎一模一样的题目:HDU-1561:The More,The Better。
# 换根法
# 例题1:
# 题目描述
给定一颗无向带权树,权值代表两点间流量的最大值,找一个节点作为根,向叶子节点流水(根节点的水流可以认为无限大),使整棵树的流水量最大。(建议自己读下acwing题面)
如图:
# 题解
这道题的思路是 二次扫描 + 换根法 。
设 $d[i]$ 为以 $i$ 为根的子树的总流量 , $f[i]$ 表示以 $i$ 为根到所有点的总流量。
以上图为例:
上图中,假如以 1 为根节点,则 $d[4]$ = 5 + 10 = 15 ; $d[1]$ = $f[1]$ = 11 + $min$ { 13 , $d[4]$ } = 24;
两次扫描处理的东西不同:
第一次扫描:取一个点 DFS 一遍搜出所有的 $d[i]$;
第二次扫描:DP求出所有的 $f[i]$ 。<= 换根法体现在这里
下面分别来讲讲两次扫描的具体过程
# 第一次扫描
取一个点 DFS 一遍搜出所有的 $d[i]$
为了方便,我们这里取 1 号点开始DFS (记住这个 “ 为了方便 ” )
一棵树本来就是具有递归性质的,所以直接按照DFS的板子打就行了。
递归边界:递归至叶子节点处停止。
递归方程:
设 $x$ 为当前节点, $j$ 为 $x$ 的儿子,则 $d[x]= \sum_{j}^{j \in x} \min { d[j] , w[x][j] } $
($w$ 数组存的是边的权值)
方程什么意思呢?
如图:
首先DFS至 2 、3、5 号节点,此时 $d[2]$ = $\infty$ , $d[3]$ = $\infty$ , $d[5]$ = $\infty$。
接下来,因为 $d[3]$ 无限大,无法全部通过管道,所以只能从 边~3,4~ 中通过 5 的流量;
同理,因为 $d[5]$ 无限大,无法全部通过管道,所以只能从 边~5,4~ 中通过 10 的流量;
这样,子树中到达 4 节点的的流量就是 5 + 10 = 15 , 所以 $d[4]$ = 15。
同理,因为 $d[4]$ =15 > $w[1][4]$ = 13,无法全部通过管道,所以只能从 边~1,4~ 中通过 13 的流量;
因为 $d[2]$ 无限大,无法全部通过管道,所以只能从 边~1,2~ 中通过 11 的流量;
这样,子树中到达 1 节点的流量就是 13 + 11 = 24 , 所以 $d[1]$ = 24。
又因为 1 号点是整棵树的根节点,所以 $f[1]$ = $d[1]$ = 24 。
如何判断叶子节点?
只需要记录下每个节点的度数就行了,如果度数为 1 ,则该节点为叶子节点。
所以,第一次扫描的代码就能打出来了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int dfs_d( int x, int fa )
{
if( deg[x] == 1 ) //deg 数组存储节点的度数
{
d[x] = 0x3f3f3f3f;
return d[x];
} //到达叶子节点时的处理,即递归边界
d[x] = 0; //将根节点初值赋为 0
for( int i = head[x] ; i ; i = nxt[i] ) //邻接表储存
{
int j = to[i]; //j 是 x 的子节点
if( j == fa ) continue;
//如果这个子节点(即下一步走的点)为自己的父节点,则跳过(防止往回递归)
d[x] += min ( w[i], dfs_d ( j, x ) ); //上面解释了
}
return d[x];
}
# 第二次扫描
DP求出所有的 $f[i]$ 。
$d[i]$ 求完了,接下来的问题是:如何DP求 $f[i]$ ?
还是用这张图来理解:
若已经求出 $f[1]$ ,接下来求 $f[4]$ (即把根节点从 1 号点上换到 4 号点上)。
首先,4 号点原来的子树中的节点到 4 号点的流量是不会变的,唯一变化的是以 4 号点为根的子树以外的节点到 4 号点的流量。
那么,怎么求这个流量呢?
要知道,除去 4 号点的子树以外的点到 1 号点(即原来的根节点)的总流量是如下部分(红框内):
很显然,只要将 $f[1]$ 减去 $d[4]$ 就好了。。。吗?
如果 $w[1][4]$ 小于 $d[4]$ 呢?
所以应是 将 $f[1]$ 减去 $d[4]$ 和 $w[1][4]$ 中小的一个。
但是这个红框内的水流一定能全部流到 4 号点吗?
当然不是,如果这个值大于 $w[1][4]$ 的话它就流不过来了。
所以红框内的水流到 4 号点时还得将这个值与 $w[1][4]$ 取 $min$。
所以,最终的转移方程就很容易地推出来了。
设 $x$ 点为 $j$ 点的父节点,则:
$f[j]=d[j]+\min{f[x]-\min{d[j],w[x][j]},w[x][j]}$
然后,读者们就会发现这个式子并不适用于叶子结点,因为叶子结点的 $d$ 值是 $\infty$ ,所以对于叶子结点还要进行特殊处理。
再次以上图为例:
其中将根转移至 2 号点上时,总流量是多少?
我们发现 2 号点没有子树,也就是说它的流量全部来自于它的父节点。所以它的 $f$ 值也就很容易地推出来了。
设 $x$ 点为 $j$ 点的父节点,则:
$f[j]=\min{w[x][j],f[x]-w[x][j]}$
OK。这样第二次扫描的代码也能打出来了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void dfs_f(int x, int fa)
{
for (int i = head[x]; i; i = nxt[i]) //邻接表储存
{
int j = to[i]; // j 是 x 的儿子
if (j == fa)continue; //防止往回扫描
if (deg[j] == 1) //如果是叶子结点
{
f[j] = min(w[i], f[x] - w[i]);
} else //如果不是叶子结点
{
f[j] = d[j] + min(f[x] - min(d[j], w[i]), w[i]);
dfs_f(j, x); //继续向下扫描
}
}
}
# 代码
这样处理以后,恭喜你,得到了一个 90 分代码!!!
90 分代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
using namespace std;
const int N = 1000010;
int T;
int n, cn;
int to[N], head[N], nxt[N], w[N], f[N], d[N], deg[N];
void add(int a, int b, int c)
{
nxt[++cn] = head[a];
to[cn] = b;
w[cn] = c;
head[a] = cn;
}
int dfs_d(int x, int fa)
{
if (deg[x] == 1)
{
d[x] = 0x3f3f3f3f;
return d[x];
}
d[x] = 0;
for (int i = head[x]; i; i = nxt[i])
{
int j = to[i];
if (j == fa)continue;
d[x] += min(w[i], dfs_d(j, x));
}
return d[x];
}
void dfs_f(int x, int fa)
{
for (int i = head[x]; i; i = nxt[i])
{
int j = to[i];
if (j == fa)continue;
if (deg[j] == 1)
{
f[j] = min(w[i], f[x] - w[i]);
} else
{
f[j] = d[j] + min(f[x] - min(d[j], w[i]), w[i]);
dfs_f(j, x);
}
}
}
int main()
{
scanf("%d", &T);
while (T--)
{
memset(head, 0, sizeof head);
memset(deg, 0, sizeof deg);
cn = 0;
scanf("%d", &n);
for (int i = 1; i < n; i++)
{
int x, y, z;
scanf("%d%d%d", &x, &y, &z);
add(x, y, z);
add(y, x, z);
deg[x]++;
deg[y]++;
}
dfs_d(1, -1);
f[1] = d[1];
dfs_f(1, -1);
int res = 0;
for (int i = 1; i <= n; i++)res = max(res, f[i]);
printf("%d\n", res);
}
return 0;
}
那么,还有一点错在哪儿呢?
仔细观察程序的 $dfs_d$ 片段,也就是第一次扫描的片段,我们发现,判断叶子结点的语句是在子程序开头的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int dfs_d( int x, int fa )
{
if( deg[x] == 1 ) //这里
{
d[x] = 0x3f3f3f3f;
return d[x];
}
d[x] = 0;
for( int i = head[x] ; i ; i = nxt[i] )
{
int j = to[i];
if( j == fa ) continue;
d[x] += min ( w[i], dfs_d ( j, x ) );
}
return d[x];
}
而且,我们在主函数中是将 1 号点看做根的。
还记得开头说的话吗?
为了方便,我们这里取 1 号点开始DFS
那如果 1 号点本身的度就只有一个呢?
所以我们应该加一段程序来找到第一个度不为 1 的节点来做初始的根。
那如果这棵树长这样怎么办?
此时,没有一个点的度是大于 1 的,那么上面的想法就不能实现了。
其实,对于这种情况,只要加一个判断就好了。
设 $root$ 为初始的根,赋初值为 $n$ + 1 。
从 1 到 n 遍历一遍,找到度大于 1 的点,将点的编号赋值给 $root$ 。如果遍历完了 $root$ 的值还是大于 $n$ 即没有找到度大于 1 的点,这时只有上图这一种情况,所以直接返回边权即为答案。
程序如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int root = n + 1;
for (int i = 1; i <= n; i++)
{
if (deg[i] != 1) {
root = i;
break; //找到了根就跳出
}
}
if (root > n) //如果没找到根
{
printf("%d\n", w[1]);
continue;
}
dfs_d(root, -1); //从根节点处开始扫描
f[root] = d[root];
dfs_f(root, -1);
如此一来,只要将主程序改一下就能得到满分程序啦!1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46int main()
{
scanf("%d", &T);
while (T--)
{
memset(head, 0, sizeof head);
memset(deg, 0, sizeof deg);
cn = 0;
scanf("%d", &n);
for (int i = 1; i < n; i++)
{
int x, y, z;
scanf("%d%d%d", &x, &y, &z);
add(x, y, z);
add(y, x, z);
deg[x]++;
deg[y]++;
}
int root = n + 1; //开始找根
for (int i = 1; i <= n; i++)
{
if (deg[i] != 1) {
root = i;
break;
}
}
if (root > n)
{
printf("%d\n", w[1]);
continue;
}
dfs_d(root, -1);
f[root] = d[root];
dfs_f(root, -1);
int res = 0;
for (int i = 1; i <= n; i++)res = max(res, f[i]); //找最大值
printf("%d\n", res);
}
return 0;
}
接下来再讲一题。
# 例题2:
其实我都不知道这道题算不算换根法,毕竟我是只蒟蒻
# 题目描述
给定一棵带权树,求每个节点能到达的最远距离。
# 输入输出
# 输入
输入文件包含多组测试数据。
第一行输入 $n$ ,表示有几个节点。
接下来 $n$ - 1 行,从 2 号点开始输入。
每行两个整数,第一个表示该节点与哪个节点相连;第二个表示连接这两个节点的边的权值是多少。
# 输出
一行一个整数,第 $i$ 行表示第 $i$ 个点能到达的最远距离。
# 题解
这题和上题很像,还是需要二次扫描和还根法。
第一次扫描:扫描出每个节点在以它为根的子树能到达的最大距离和次大距离,并标记出最大距离经过了该节点的哪个儿子节点。
第二次扫描:求出每个节点通过它的父节点能到达的最大距离。
接下来详细讲讲两次扫描如何进行。
# 第一次扫描
第一次扫描的过程和求树的直径很像。
求树的直径:
设 $f[i][0]$ 为以 $i$ 节点为根节点的子树中, $i$ 到叶子节点的最大距离;
设 $f[i][1]$ 为以 $i$ 节点为根节点的子树中, $i$ 到叶子节点的次大(第二大)距离。
令 $j$ 为 $x$ 的儿子。
设 $w[j][x]$ 为 $j$ 到 $x$ 的路径长度。
下面用代码解释:1
2
3
4
5
6
7
8
9if( f[x][0] < f[j][0] + w[j][x] )
{//如果x节点到叶节点的最大距离 小于 j节点到叶节点的最大距离 加上 x节点到j节点的距离
f[x][1]=f[i][0];//将x节点到叶节点的最大值变成次大值
f[x][0]=f[j][0]+w[j][x];//更新最大值
}
else if( f[x][1] < f[j][0] + w[j][x] )
{//如果x的最大值大于j的,但x的次大值小于j
f[x][1]=f[j][0]+w[j][x];//更新次大值
}
怎么样是不是很像?
所以只需要在原代码上加一个DFS和记录最大路径经过哪个儿子节点就好了。其实是我懒
于是这段代码加上DFS后就是这个亚子的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22int dfs1(int x, int fa) //返回的是 x 节点在其子树中的最大距离
{
if (f[x][0] != 0x3f3f3f3f)return f[x][0]; //如果x点走过了,则直接返回最大距离
f[x][0] = f[x][1] = f[x][2] = v[x] = 0;
for (int i = head[x]; i; i = nxt[i]) //邻接表储存
{
int j = to[i]; // j 为 x 的子节点
if (j == fa)continue; //防止往回扫描
if (f[x][0] < dfs1(j, x) + w[i])
{ //如果x节点在其子树中的最大距离 小于 j节点在其子树中的最大距离 加上 x 到 j 的距离
v[x] = j; //记录最大距离经过哪个儿子节点
f[x][1] = f[x][0]; //更新次大值
f[x][0] = f[j][0] + w[i]; //更新最大值
} else if (f[x][1] < f[j][0] + w[i])
{ //如果x的最大值大于j的,但x的次大值小于j
f[x][1] = f[j][0] + w[i]; //更新次大值
}
}
return f[x][0]; //返回最大值
}
OK,接下来是第二次扫描。
# 第二次扫描
设 $f[i][2]$ 为 $i$ 节点通过其父节点能到达的最大距离。
此时有两种情况:父节点的最大距离经过此节点,则此点的 $f[i][2]$ 为父节点的次大距离和父节点通过它的父节点能到的最大距离的更大的一个。
此时方程如下:
令 $j$ 为 $x$ 的儿子。
$f[i][2]=\max{f[x][2],f[x][1]}$
若父节点的最大距离未经过此点,则此点的 $f[i][2]$ 为父节点的最大距离和父节点通过它的父节点能到的最大距离的更大的一个。
同样,此时方程如下:
$f[i][2]=\max{f[x][2],f[x][0]}$
所以第二次扫描的代码也很容易地打出来了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18void dfs2(int x, int fa)
{
for (int i = head[x]; i; i = nxt[i]) //邻接表储存
{
int j = to[i]; // j 为 x 的子节点
if (j == fa)continue; //防止往回扫描
if (j == v[x])
{ //如果父节点的最大距离路径经过了此节点
f[j][2] = max(f[x][2], f[x][1]) + w[i];
} else
{ //否则
f[j][2] = max(f[x][2], f[x][0]) + w[i];
}
dfs2(j, x); //继续向下扫描
}
}
# 代码
通篇代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
using namespace std;
const int N = 100010;
int n, x, y, cn;
int head[N], to[N], nxt[N], w[N], f[N][3], v[N];
void add(int a, int b, int c)
{
nxt[++cn] = head[a];
to[cn] = b;
w[cn] = c;
head[a] = cn;
}
int dfs1(int x, int fa)
{
if (f[x][0] != 0x3f3f3f3f)return f[x][0];
f[x][0] = f[x][1] = f[x][2] = v[x] = 0;
for (int i = head[x]; i; i = nxt[i])
{
int j = to[i];
if (j == fa)continue;
if (f[x][0] < dfs1(j, x) + w[i])
{
v[x] = j;
f[x][1] = f[x][0];
f[x][0] = f[j][0] + w[i];
} else if (f[x][1] < f[j][0] + w[i])
{
f[x][1] = f[j][0] + w[i];
}
}
return f[x][0];
}
void dfs2(int x, int fa)
{
for (int i = head[x]; i; i = nxt[i])
{
int j = to[i];
if (j == fa)continue;
if (j == v[x])
{
f[j][2] = max(f[x][2], f[x][1]) + w[i];
} else
{
f[j][2] = max(f[x][2], f[x][0]) + w[i];
}
dfs2(j, x);
}
}
int main()
{
while (scanf("%d", &n) == 1 && n)
{
memset(f, 0x3f, sizeof f);
memset(head, 0, sizeof head);
memset(v, 0, sizeof v);
cn = 0; //初始化
for (int i = 2; i <= n; i++)
{
scanf("%d%d", &x, &y);
add(i, x, y); //邻接表储存
add(x, i, y);
}
dfs1(1, 0);
dfs2(1, 0);
//两次扫描
for (int i = 1; i <= n; i++)
{
printf("%d\n", max(f[i][0], f[i][2])); //max{f[i][0], f[i][2]} 即为最大距离
}
}
return 0;
}
OK,我们的换根法就讲完啦!
接下来的又是一些例题。
# 习题 习题 更多的习题
#
因为是英文题面,我这里题目描述就写详细一点好了。
# 题目描述
给定一棵无权树。将一个节点的 Balance 定义为从该树中删除该节点所创建的森林中最大的树的大小。
求出最小的balance值和其所对应的节点编号。
# 输入
输入文件的第一行包含一个整数 t(1 <= t <= 20),即测试样例的数量。每个测试样例的第一行包含一个整数 N(1 <= N <= 20,000),即节点的数量。接下来的 N-1行,每行两个节点编号,表示一条边的两个端点。没有一条边会被列出两次。
# 输出
对于每个测试样例,输出一行包含两个整数,即具有最小Balance的节点编号和对应的Balance值。
# 题解
不是我说,但是这是真的水
又一题换根法的应用。
不过比起前面几题,换根味道不是很浓,而且这题也很水
只需要一次DFS。
设 $f[i]$ 为 $i$ 号点的 Balance 值;
设 $son[i]$ 为以 $i$ 号点为根的子树的节点数;
设 $j$ 为 $x$ 的儿子节点。
那么根据定义,可得到如下公式:
$son[x]=\sum_{j}^{j \in x} son[j]+1$
即 $son[x]$ 等于以它的每个子节点为根的子树的节点数之和加一(加一是因为包括它本身)。
我们只需要在初始化 $son$ 数组时将每个值都赋值为 1 就可以在DFS中免掉加一的操作。
接下来是 $f$ 数组。
在算 $f[x]$ 时首先考虑 $x$ 的子树中最大的一个,然后考虑除了以 $x$ 点为根的子树外的树的最大值;
将两个最大值比较,取大者即为 $f[x]$ 。
所以,$f[x]$ 的方程也列出来了:
$f[x]=\max {f[x],son[j]}(j \in x)$
$f[x]=\max {f[x],n-son[x]}$
SO,这道题就这样了。
# 代码
1 |
|
水题讲完啦
NNNNNEXT!!!!
福利(做一题赚一题):一道和这题几乎一模一样的题:POJ-3107:Godfather(就好像 选课 和 The More,The Better 的区别)。
#
一道水题。
# 题目描述
给你一棵带权树,找出节点数在 K 内的最大子树。
# 输入
多组测试样例。
每组样例第一行两个整数,表示节点总数 N (1 <= N <= 100)和 K(1 <= K <= N) 。
第二行 N 个整数,表示每个节点的权值(节点从 0 开始编号)。
后面 N - 1 行,每行两个整数,表示一条边的两个端点。
# 输出
每个样例一行输出,表示最大权值的子树的权值和。
# 题解
又一道树上背包,而且比前面的简单多了。
打腻了邻接表,这道题换个口味。
于是乎,可以用 VECTOR 来做。
即,用 VECTOR 存储每个节点的儿子,用时直接取出就好了。
下面直接在代码中解释:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
using namespace std;
const int N = 110;
int n, m;
int f[N][110];
vector < int > son[N]; //STL 容器:向量 (STL太香啦!!!)
void dfs(int x, int fa)
{
for (int i = 0; i < son[x].size(); i++)
{
int j = son[x][i];
if (j == fa)continue;
dfs(j, x);
for (int p = m; p > 0; p--)
{ //01背包,倒着防止重复计算出现错误
for (int k = 0; k < p; k++)
{ //这里 k 必须从小到大遍历,否则会发生 神 奇 的 错 误(我在这卡了那么 一 小 会 儿 吧)
f[x][p] = max(f[x][p], f[x][p - k] + f[j][k]);
//普通得不能再普通地更新最大值
}
}
}
}
int main()
{
while (scanf("%d%d", &n, &m) != EOF)
{ //多组测试样例
memset(f, -1, sizeof f);
for (int i = 0; i < n; i++)
{
son[i].clear();
} //初始化
for (int i = 0; i < n; i++)scanf("%d", &f[i][1]);
for (int i = 1; i < n; i++)
{
int x, y;
scanf("%d%d", &x, &y);
son[x].push_back(y);
son[y].push_back(x); //无向边储存
}
dfs(0, -1); //从 0 号点开始递归
int ans = -1;
for (int i = 0; i < n; i++)
{
ans = max(ans, f[i][m]);
} //找最大值
printf("%d\n", ans);
}
return 0;
}
I AM SO WATERY!!!
#
跟 POJ-1655:Balancing Act 一样,只要在最后输出时判断一下最大值有没有超过 n/2 就好了,如果没超过就直接输出。
代码这里就不打了,留给读者做习题好了。
#
终于有一道不是那么水的题啦!
# 题目描述
给定一棵无权树,求出至少要删多少条边才能得到一棵节点数为 m 的子树。
# 题解
也是一道树上背包的题目。
背包容量是节点数 m ,每个物品的重量为 1 。
其实这题还是和前几道树上背包很像,只有几处不同。
这道题也只需要一次DFS(有没有发现树形DP通常都用DFS来迭代)。
设 $f[i][j]$ 为以 $i$ 为根的子树取 $j$ 个节点至少需要删去几条边(包括子树与父节点间的边)。
那么,由定义得, $f[i][1]$ 就等于 $i$ 点的度数。
如图: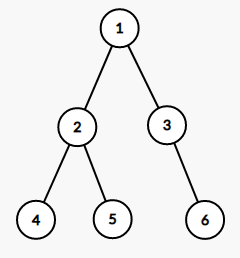
此时的 $f[2][1]$ 就等于 3 ,即 1-2 边, 2-4 边, 2-5 边。
那么,将 $m$ 条边从 1 号点分下去,一直分到叶子节点或者分完了为止。
所以,转移方程也比较容易地写出来了:
$j$ 为 $x$ 的儿子。
$f[x][p]=\min{f[x][p],f[x][p-k]+f[j][k]-2},(1<=p<=m,1<=k<=p)$
这里面的 -2 是什么意思呢?
我们把上面的转移方程换成下面的样子看看:
$f[x][p]=\min{f[x][p],(f[x][p-k]-1)+(f[j][k]-1)},(1<=p<=m,1<=k<=p)$
那这里把两个分别都 -1 是什么意思呢?
如图所示: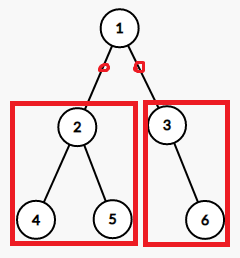
我们之前定义 $f$ 数组储存的是最少去掉的边,如在此图中, $f[2]$和$f[3]$ 分别将两个画了小红点的边去掉了。但是我们在计算时需要将这些边算上(要不然怎么连接子树)。所以要分别 -1。
OK,思想讲完了,下面直接上代码吧。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
using namespace std;
const int N = 400;
int n, m, cn, x, y;
int nxt[N], f[N][N], to[N], head[N], a[N], num[N], ans = 0x3f3f3f3f;
//num 数组储存每个节点的度数
void add(int x, int y) //邻接表储存
{
to[++cn] = y;
nxt[cn] = head[x];
head[x] = cn;
num[x]++;
}
int dfs(int x, int fa)
{
f[x][1] = num[x];
for (int i = head[x]; i; i = nxt[i]) //邻接表储存
{
int j = to[i]; // j 为 x 的儿子
if (j == fa)continue; //防止往回 DFS
dfs(to[i], x);
for (int p = m; p >= 1; p--)
{ //背包
for (int k = 1; k <= p; k++)
{ //分配边数
f[x][p] = min(f[x][p], f[x][p - k] + f[j][k] - 2); //转移
}
}
}
return ans = min(ans, f[x][m]);
}
int main()
{
scanf("%d%d", &n, &m);
memset(f, 0x3f, sizeof(f));
for (int i = 1; i < n; i++)
{
scanf("%d%d", &x, &y);
add(x, y);
add(y, x);
}
printf("%d", dfs(1, 0));
return 0;
}
OH,YEAH!!!NNNNNNNEXT!!!
#
# 题目描述
给定一棵树,节点数 n <= 1000(每个节点的分支 <= 8),一只蜗牛在根(1 号节点)处,他要到叶子节点上去找房子,而有几个节点上(根节点上没有)有虫子告诉你房子在不在这棵子树上,求出蜗牛最快找到房子的路径的期望值。
# 输入
多组样例。
每组样例第一行一个整数 n 表示节点数,接下来 n 行一个整数 $a$ 和一个字母 $b$。
第 $i$ 行的整数 $x$ 表示第 $i$ 个节点的父节点是 $x$ ,字母 $b$ 为 Y 时表示 $i$ 号节点有虫子提供信息,为 N 时则是没有。
($i$ = 1 的那行输入其实可以忽略)
n = 0 表示输入结束。
# 输出
对于每个样例,输出一行包含一个四位小数的浮点数,表示最小的期望值。
# 题解
首先,啥是期望值?
百度百科定义如下:
数学期望(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。它反映随机变量平均取值的大小。
在这题中可以把它理解成加权平均值。(两者不一样,只是这题较特殊)(其实我到现在都不是很明白期望值是个什么东西)
说不明白,举个例子吧。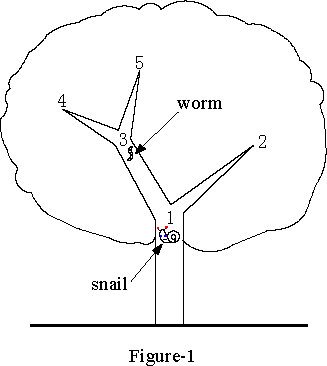
snail - 蜗牛,worm - 虫子。
如图所示,蜗牛在 1 号点,房子在 2、4、5 中的某一点。一只虫子在 3 号点,它可以告诉蜗牛房子是否在第4和第5点中的某一点(房子是否在此子树上)。因此,蜗牛可以选择两种策略。
他可以先去 2 号点。如果他在那里找不到房子,他应该回到 1 号点,然后通过3号点到达 4(或5)号点。如果还是不行,他就得返回3点,然后去5点(或4点),在那里他无疑会找到房子。在这个选择中,蜗牛所走的距离为 1、4、6,分别对应于房子在2、4(或5)、5(或4)点的情况。所以期望值是(1+4+6)/3=11/3。
显然,这种策略并没有充分利用虫子给的的信息。如果蜗牛先去3号点,从蠕虫那里得到有用的信息,然后选择回到 1 号点,然后去 2 号点,或者去 4 号或 5 号点碰碰运气,那么他所走的距离将是 2、3、4,对应于房子的不同位置。在这样的策略中,数学期望值将是(2+3+4)/3=3,而这正是蜗牛应该在树上搜寻的路线。
接下来,直入主题。
设 $f[i][0]$ 为在以 $i$ 为根的子树中没有找到房子的步数的总和;
设$f[i][1]$ 为在以 $i$ 为根的子树中找到房子的步数的总和;
设 $lea[i]$ 为以 $i$ 为根的子树中的叶子节点数;
设 $bug[i]$ 储存第 $i$ 个节点处是否有虫子。
设 P~i~ 为房子在 $i$ 子树上的概率,两个节点分别为 $x$ 和 $y$ 。
题目要求我们找到最小的期望值,那么我们就应该比较以下两种情况哪一种的期望值更小:
先 $x$ 后 $y$ :
$f[x][1] P~x~+(f[x][0]+2+f[y][1]) P~y~$
先 $y$ 后 $x$:
$f[y][1] P~y~+(f[y][0]+2+f[x][1]) P~x~$
这里结合定义稍微想一下应该就能出来了,我就不多说了 (就是懒呗) 。
通过观察得,比较上面两个式子的大小其实就是比较下面两个式子的大小:
$(f[x][0]+2) P~y~ 和 (f[y][0]+2) P~x~$
这里 +2 是连接该子树的边的来回两次。
按照这个式子将子树排序,按照顺序遍历后得到的结果就是最优的了。
然后来推转移方程。
($j$ 为 $x$ 的儿子)
首先,根据定义能得到:
$f[x][0]=\sum{f[j][0]+2}(前提是此时bug[x]=0,即此处没有虫子)$
为什么要 +2 上面已经解释了。
当此处有虫子时也就是 $bug[x]$ = 1 时 $f[x][0]$ = 0
这是因为当这里有虫子时,虫子会告诉你房子在不在这棵子树上。
当目前节点为叶子节点时,$f[x][0]=f[x][1]=0$
在某个分叉处,我们枚举房子在此子树上的各个叶子节点时 所需的距离。
方程如下:
$f[x][1] += f[x][0] lea[q[x][i]] + f[q[x][i]][1] + lea[q[x][i]]$
$q$ 储存 $x$ 的儿子。
也可以写成:
$f[x][1] += (f[x][0]+1) lea[q[x][i]] + f[q[x][i]][1]$
因为 $f[x][0]$ 初始化为 0 ,且与 $f[x][1]$ 同步更新,所以此时只需将它 +1 后乘上 该子树的叶子节点数 再加上找到房子的路径长度就行了。
为什么要乘上叶子结点数? 因为在某一个叶子结点找到房子时 其他的路径可以是任意顺序的。如有三个节点 1 , 2,3 。房子在 1 号节点上,那么找到房子的路径可以是 1 或 21 或 31 或 231 或 321 。
这种大家还是自己画个图推一下比较好 (我又懒又菜,只能水一下了)
然后就水完了
此题部分参考此博客
下面是代码:
# 代码
1 |
|
这题挺不错的,但我讲的不怎么好,敬请谅解,毕竟我是只蒟蒻。
下一题。
#
# 题目描述
给定一棵树,求最少连多少条边,使得每个点在且仅在某一个环内。(一个环至少三个点)
# 题解
这道题挺好的 (整了我好久)
参考博客
首先,找到DP的状态。
设 $f[x][0]$ 为以 $x$ 为根的子树中,让每一个节点各自在一个环中需要加的边数。
设 $f[x][1]$ 为以 $x$ 为根的子树中,让除了根节点以外的节点各自在一个环中需要加的边数。
设 $f[x][2]$ 为以 $x$ 为根的子树中,让除了根节点以及与根相连的一条链(加上根节点至少两个节点)以外的节点各自在一个环中需要加的边数。
状态有了,怎么转移呢?
四种转移状态。
如图:
(借用其他大佬的图片一用)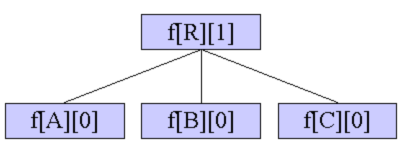
根R的所有子树自己解决(取状态0),转移到R的状态1。即R所有的儿子都变成每个顶点恰好在一个环中的图,R自己不变。
即 $f[x][1]$ 可以分为它的子节点的 $f[son][0]$ 之和。
根R的k-1个棵树自己解决,剩下一棵子树取状态1和状态2的最小值,转移到R的状态2。剩下的那棵子树和根R就构成了长度至少为2的一条链。
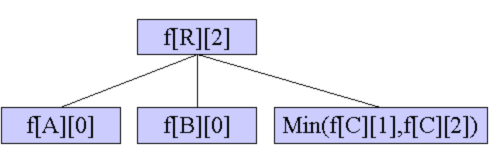
让其中一个子节点(或与子节点相连的链)与根节点构成一条链。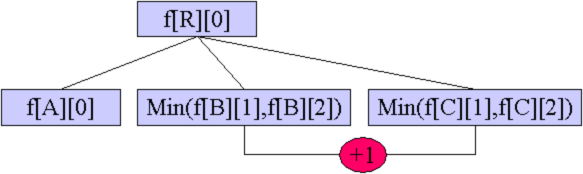
根R的k-2棵子树自己解决,剩下两棵子树取状态1和状态2的最小值,在这两棵子树之间连一条边,转移到R的状态0。
让其中两个子节点(或者与子节点相连的链)与根节点组成一个环(因为一个环至少有三个节点)。
根R的k-1棵子树自己解决,剩下一棵子树取状态2(子树里还剩下长度至少为2的一条链),在这棵子树和根之间连一条边,构成一个环,转移到R的状态0。
让其中一个子节点(或与子节点相连的一条链)加上根节点再加一条边组成一个环。
那么转移方程怎么写呢?
我们设 $sum$ 是 $x$ 节点的 $f[j][0]$ 的总和( $j$ 是 $x$ 的儿子)
设 $min1$ 为 最小的一个 $f[j][1]$ 或 $f[j][2]$ 减去 $f[j][0]$ 的值。
设 $min2$ 为 次小的一个 $f[j][1]$ 或 $f[j][2]$ 减去 $f[j][0]$ 的值($j$ 与 $min1$ 的不是同一个)。
设 $min3$ 为最小的一个 $f[j][2]$ 减去 $f[j][0]$ 的值。
为啥要减去 $f[j][0]$?
因为在求 $sum$ 时已经把 $f[j][0]$ 算上了,如果此处不减去 $f[j][0]$,在最后相加时会重复计算一个 $f[j][0]$ 。
也就是说,$min1、min2$ 实际上储存的是 最小的 $f[j][1]$ 或 $f[j][2]$ 以及 次小的 $f[j][1]$ 或 $f[j][2]$ 只是为了避免重复就减去了$f[j][0]$(具体等下看代码)。
当 $x$ 节点的 $sum$ 、$min1$ 、$min2$ 、$min3$ 都求出时:
根据定义得
$f[x][1]=sum$
$f[x][2]=sum+min1$
此时就能看出求 $min1、min2$ 时为什么要减去 $f[j][0]$ 了。
以及有两种情况的 $f[x][0]$:
$f[x][0]=sum+1+\min(min1+min2 , min3)$
在两个情况中选择较小的一个。
下面见代码。
# 代码
1 |
|
接下来是今天的最后一题。
#
# 题目描述
在一棵树形的城市群中建立一些消防站(每个城市中建立消防站所需的花费不同),但每个城市有一个到消防站的最大距离限制,求需要的最小花费。
# 输入
多组测试数据。
第一行输入测试数据组数。
每族第一行一个整数 N,表示有几座城市。
第二行 N 个整数,表示在每个城市中建立消防站需要花费的金额。
第三行 N 个整数,表示每个城市到消防站的最大距离限制。
接下来 N - 1 行每行三个整数u、v、L,表示在 u 城市与 v 城市间有一条长度为 L 的路径。
# 输出
每组数据输出一行,表示最小的花费。
# 题解
这题好难啊
以后有空 (下辈子) 再来补吧。
OK
今天的树形DP打完了。
你学废了吗?
~Dumby_cat原创~